
Challenge
We were approached by a federal customer whose transcript demand had outstripped its capability. They were looking for a way to reduce the time needed to produce a transcript without yielding accuracy. They also hoped that a technical solution could connect related documents. We knew this was the “killer feature” given the fact that linking related transcripts and classifying data was an additional process with its own set of risks.
Process
Our research began by going deep on transcribing in general. We wanted to learn if a common toolkit or software stack existed. Was there an accepted industry standard(s) for accuracy? What techniques ensured, or even increased, speed? Where was this type of work typically performed?

the transcription workflow
The button’s link behavior instead took them out of the plan shopping flow to a page that enthusiastically congratulated them on finding a plan they like with a to-do list, but no way clear way of recalling that plan.

Users could choose to toggle the waveform view on/off
The transcript list view presented a different challenge. We wanted this page to visually offset the overall data richness of the application. Cards accomplished this goal, but one variable was not considered in the prototypes — what happened when there were 100+ transcripts? The card UI became overwhelming and crumbled under the weight.
Much of the functionality that anchored the initial release of TEXTSURE was the direct result of research and iteration.
The drawer became the primary way of interacting with a transcript’s meta data without leaving the editor. Collections, speakers, tags, and other data that described the transcript could all be viewed, changed, and augmented in the context of the transcript during editing.

Using tags and other unstructured data gave us the power to group otherwise unrelated objects. We intentionally steered the Add Transcript UI toward only requiring the data that we needed to process the file and fields where data types were important (date, number, etc). All other data would be unstructured text objects.
A final transcript might contain many instances where discrete pieces of a recording were assigned characteristics — pertinent, privileged, further review, etc. These could be also be assigned as tags so pulling a list of privileged conversations could be done with a single click.
Low-fidelity prototypes were produced for each step of the process. We chose Figma for its powerful prototyping, collaboration, and developer handoff features.

Displaying relevant workflow information was key after login
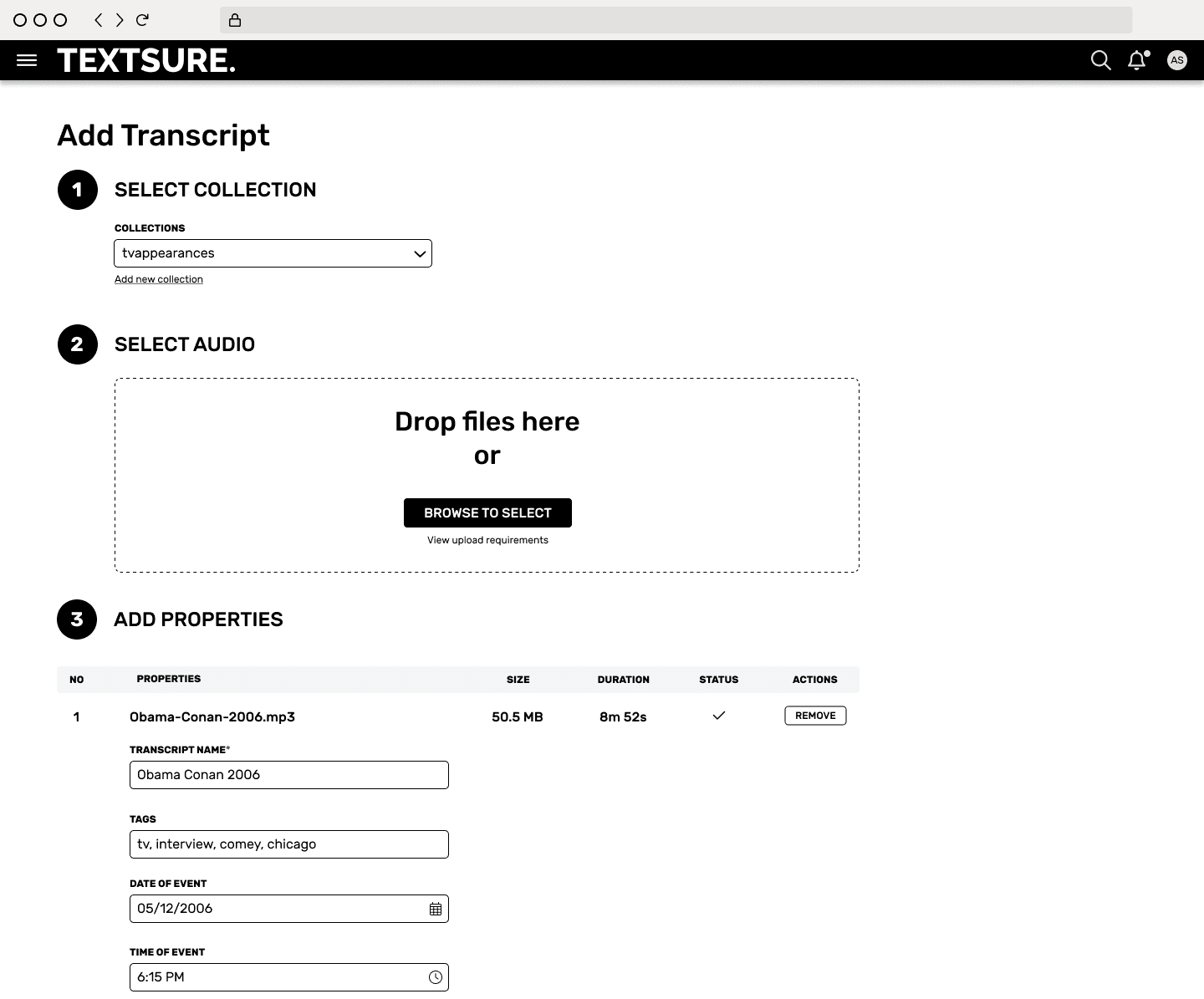
Upload audio and add a transcript

View and update transcript details asynchronously while editing transcript

Build and preview a PDF transcript for downloading
Outcome
A common metric used for transcript accuracy is the Word Error Rate (WER). A human can average a slightly lower WER (~ 3%), but the benefits of only needing minor edits greatly outweighs the cost of manually producing a transcript. One user reported an 89% time savings when transcribing a 15-minute conversation using TEXTSURE.
The asynchronous nature of cloud processing and user review has been a productivity boon. Team members are now able to queue multiple files that complete in the background, freeing them to work in more valuable ways.
The product design team learned our own valuable lesson about how much data is right for the prototype.